Java避坑 .xlsx和.xls文件读取注意事项 在不确定用户上传至系统的Excel文件是.xlsx格式的文件还是.xls格式的文件时,会遇到报以下错误信息的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import org.apache.poi.hssf.usermodel.HSSFWorkbook;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import org.apache.poi.ss.usermodel.Workbook;import java.io.FileInputStream;import java.io.InputStream;public class ReadExcelFileByHSSFworkbookError public static void main (String[] args) String filePath = "D:\\tmp\\test.xlsx" ; Workbook workbook = new HSSFWorkbook(); try (InputStream fileInputStream = new FileInputStream(filePath)) { workbook = new HSSFWorkbook(fileInputStream); Sheet sheet = workbook.getSheetAt(0 ); Row firstRow = sheet.getRow(0 ); Cell firstCell = firstRow.getCell(0 ); String cellValue = firstCell.getStringCellValue(); System.out.println("第一行第一列的文字内容为: " + cellValue); workbook.close(); } catch (Exception e) { e.printStackTrace(); } } }
1 2 3 org.apache.poi.poifs.filesystem.OfficeXmlFileException: The supplied data appears to be in the Office 2007 + XML. You are calling the part of POI that deals with OLE2 Office Documents. You need to call a different part of POI to process this data (eg XSSF instead of HSSF)
遇到这个问题是因为代码中处理传入的Excel的类和Excel的文件类型不匹配。
HSSFworkbook对象解析的Excel为.xls格式 XSSFworkbook对象解析的Excel为.xlsx格式 xls导出最大行数为65535,xlsx最大行数为104万
解决方法有两种,首先介绍第一种,手动在代码中加if-else判断文件名中包含哪种类型文件的后缀,使用对应的解析器进行解析,如果解析失败(用户手动改后缀名,强行修改文件后缀以为修改了文件格式,但文件的字节码没变,所以解析失败;以另存为的方式保存为另一种格式的Excel文件则不会出现解析失败的问题)使用try-catch兜底,使用另外一种格式的解析器进行解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import org.apache.poi.hssf.usermodel.HSSFWorkbook;import org.apache.poi.ss.usermodel.*;import org.apache.poi.xssf.usermodel.XSSFWorkbook;import java.io.FileInputStream;import java.io.InputStream;public class ReadExcelFileByHSSFworkbook public static void main (String[] args) String filePath = "D:\\tmp\\test.xlsx" ; String extension = getFileExtension(filePath); Workbook workbook = new HSSFWorkbook(); try (InputStream fileInputStream = new FileInputStream(filePath)) { if ( "xlsx" .equals(extension)){ try { workbook = new XSSFWorkbook(fileInputStream); }catch (Exception e){ System.out.println(".xlsx是.xls手动改的后缀 而不是通过另存为的方式同步修改文件本身的字节码" ); workbook = new HSSFWorkbook(fileInputStream); } } else if ("xls" .equals(extension) ){ try { workbook = new HSSFWorkbook(fileInputStream); }catch (Exception e){ System.out.println(".xls是.xlsx手动改的后缀 而不是通过另存为的方式同步修改文件本身的字节码" ); workbook = new XSSFWorkbook(fileInputStream); } } Sheet sheet = workbook.getSheetAt(0 ); Row firstRow = sheet.getRow(0 ); Cell firstCell = firstRow.getCell(0 ); String cellValue = firstCell.getStringCellValue(); System.out.println("第一行第一列的文字内容为: " + cellValue); workbook.close(); } catch (Exception e) { e.printStackTrace(); } } private static String getFileExtension (String fileName) int lastIndexOfDot = fileName.lastIndexOf("." ); if (lastIndexOfDot == -1 ) { return "" ; } else { return fileName.substring(lastIndexOfDot + 1 ); } } }
第二种解决方式为使用WorkbookFactory对Excel文件进行解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import org.apache.poi.ss.usermodel.*;import java.io.FileInputStream;import java.io.InputStream;public class ReadExcelFileByWorkbookFactory public static void main (String[] args) String filePath = "D:\\tmp\\test.xlsx" ; try (InputStream fileInputStream = new FileInputStream(filePath)) { Workbook workbook = WorkbookFactory.create(fileInputStream); Sheet sheet = workbook.getSheetAt(0 ); Row firstRow = sheet.getRow(0 ); Cell firstCell = firstRow.getCell(0 ); String cellValue = firstCell.getStringCellValue(); System.out.println("第一行第一列的文字内容为: " + cellValue); workbook.close(); } catch (Exception e) { e.printStackTrace(); } } }
Lombok之@SneakyThrows 作用为减少程序的异常捕获。
我们现在写代码,如果遇到异常,通常需要try catch,或者直接throws抛给上一层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class SneakyThrowsTest public static void main (String[] args) Class clz = null ; try { clz = Class.forName("JavaKnowledge.KnowledgePoints.SneakyThrowsTest.SneakyThrowsTest" ); System.out.println(clz.getName()); Thread.sleep(3000 ); System.out.println("3秒已过......" ); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 10 11 public class SneakyThrowsTestSecond public static void main (String[] args) throws ClassNotFoundException, InterruptedException Class clz = Class.forName("JavaKnowledge.KnowledgePoints.SneakyThrowsTest.SneakyThrowsTestSecond" ); System.out.println(clz.getName()); Thread.sleep(3000 ); System.out.println("3秒已过......" ); } }
有时程序里有异常处理较多的时候,直接catch Exception e ,简单直接粗暴的捕获异常。这些平时对异常的处理有点麻烦,所以出现了@SneakyThrows,看下使用示例:
1 2 3 4 5 6 7 8 9 10 11 public class SneakyThrowsTestThird @SneakyThrows public static void main (String[] args) Class clz = Class.forName("JavaKnowledge.KnowledgePoints.SneakyThrowsTest.SneakyThrowsTestThird" ); System.out.println(clz.getName()); Thread.sleep(3000 ); System.out.println("3 second later......" ); } }
实践可知:直接在方法上面加上@SneakyThrows即可,不需要再throws抛出异常。@SneakyThrows直接把捕获异常的代码嵌入到了class文件里。
1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) try { Class clz = Class.forName("JavaKnowledge.KnowledgePoints.SneakyThrowsTest.SneakyThrowsTestThird" ); System.out.println(clz.getName()); Thread.sleep(3000 ); System.out.println("3 second later......" ); } catch (Throwable var2) { throw var2; } }
也就是说,并不是我们忽略了异常,而是类似于Lombok的@Data注解,在编译时就已经把处理的代码嵌入到了class内。我们也可以自定义需要@SneakyThrows处理的异常,比如只需要该注解帮助我们处理Thread.sleep的异常,关于Class.forName的异常我们需要额外做处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class SneakyThrowsTestFourth @SneakyThrows(InterruptedException.class) public static void main (String[] args) Class clz = null ; try { clz = Class.forName("JavaKnowledge.KnowledgePoints.SneakyThrowsTest.SneakyThrowsTestFourth" ); System.out.println(clz.getName()); } catch (ClassNotFoundException e) { System.out.println("类未找到:" + e); } Thread.sleep(3000 ); System.out.println("3秒已过......" ); } }
@SneakyThrows注解的定义(需要下载源码才能看到 ):
1 2 3 4 5 @Target({ElementType.METHOD, ElementType.CONSTRUCTOR}) @Retention(RetentionPolicy.SOURCE) public @interface SneakyThrows { Class<? extends Throwable>[] value() default {Throwable.class}; }
说明该注解可以加在方法或者构造器上,value是Class<? extends Throwable>[],是Throwable异常的子类数组。这个注解的原理在于Lombok.sneakyThrow(t);中,利用泛型将我们传入的Throwable强转为RuntimeException。虽然事实上我们不是RuntimeException。但是没关系。因为JVM并不关心这个。泛型最后存储为字节码时并没有泛型的信息。这样写只是为了骗过javac编译器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Lombok public Lombok () } public static RuntimeException sneakyThrow (Throwable t) if (t == null ) { throw new NullPointerException("t" ); } else { return (RuntimeException)sneakyThrow0(t); } } private static <T extends Throwable> T sneakyThrow0 (Throwable t) throws T { throw t; } ...... }
注意事项:**@SneakyThrows虽然帮助我们节省了手动throws抛出异常,但如果有些异常需要再编译阶段就识别到并处理,那加了这个注解将会无法感知这些异常的存在。另外如果代码中不存在异常情况,加了@SneakyThrows注解会一定程度上误导其他阅读你的代码的人这里存在异常情况**。所以还是要根据实际情况再决定是否使用@SneakyThrows注解。
Varchar长度可变,那我要不要定到最大? Varchar中指定的长度越大,会消耗更多的内存 ,因为MySQL通常会分配固定大小的内存块来保存数据 。当然,在没拿到存储引擎存储的数据之前,并不会知道我这一行拿出来的数据到底有多长,可能长度只有1,可能长度是500,那怎么办呢?那就只能先把最大空间分配好了,避免放不下的问题发生,这样实际上对于真实数据较短的Varchar确实会造成空间的浪费。
举例:我向数据类型为:Varchar(1000)的列插入了1024行数据,但是每个只存一个字符,那么这1024行真实数据量其实只有1K,但是我却需要准备好1M的内存 去适应他。所以最好的策略是只分配真正需要的空间。
Char和Varchar有哪些区别 1.固定长度 和 可变长度 Varchar
Varchar类型用于存储可变长度字符串,是最常见的字符串数据类型。它比固定长度类型更节省空间,因为它仅使用必要的空间(根据实际字符串的长度改变存储空间)。
Char
Char类型用于存储固定长度字符串 :MySQL总是根据定义的字符串长度分配足够的空间。当存储Char值时,MySQL会删除字符串中的末尾空格 。
2.存储方式 Varchar
Varchar需要使用1或2个额外字节记录字符串的长度 :如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。假设采用latinl字符集,一个Varchar(10)的列需要11个字节的存储空间。Varchar(1000)的列则需要1002 个字节,因为需要2个字节存储长度信息。
Varchar节省了存储空间,所以对性能也有帮助。但是,由于行是变长的,在Update时可能使行变得比原来更长,这就导致需要做额外的工作。如果一个行占用的空间增长,并且在页内没有更多的空间可以存储,在这种情况下,不同的存储引擎的处理方式是不一样的。例如,MylSAM会将行拆成不同的片段存储,InnoDB则需要分裂页来使行可以放进页内。
Char
Char适合存储很短或长度近似的字符串 。例如,Char非常适合存储密码的MD5值,因为这是一个定长的值 。对于经常变更的数据,Char也比Varchar更好,因为定长的CHAR类型不容易产生碎片 。对于非常短的列,Char比Varchar在存储空间上也更有效率。例如用Char(1)来存储只有Y和N的值,如果采用单字节字符集只需要一个字节,但是Varchar(1)却需要两个字节,因为还有一个记录长度的额外字节。
3.存储容量 Char
对于Char类型来说,最多只能存放的字符个数为255,和编码无关,任何编码最大容量都是255 。
Varchar
MySQL行默认最大65535字节,是所有列共享(相加)的,所以Varchar的最大值受此限制。表中只有单列字段情况下,Varchar一般最多能存放(65535 - 1 - 2)个字节,Varchar的最大有效长度通过最大行数据长度和使用的字符集来确定,通常的最大长度是65532个字符(当字符串中的字符都只占1个字节时,能达到65532个字符) 。
为什么是65532个字符? 算法如下(有余数时向下取整):
最大长度(字符数) = (行存储最大字节数 - NULL标识列占用字节数 - 长度标识字节数) / 字符集单字符最大字节数
NULL标识列占用字节数 :允许NULL时,占1字节
长度标识字节数 :记录长度的标识,长度小于等于255(2的8次方)时,占1字节(1个字节是8个比特,即:1byte = 8bit);小于65535时(2的16次方),占2字节
版本变化
Varchar类型在4.1和5.0版本发生了很大的变化,使得情况更加复杂。从MySQL 4.1开始,每个字符串列可以定义自己的字符集和排序规则 。这些东西会很大程度上影响性能。
4.0版本及以下,MySQL中Varchar长度是按字节 ,如varchar(20),指的是20字节;
5.0版本及以上,MySQL中Varchar长度是按字符 。如varchar(20),指的是20字符。
当然,行总长度还是65535字节 ,而字符和字节的换算,则与编码方式有关 ,不同的字符所占的字节是不同的。编码划分如下:
1 2 3 4 5 6 7 8 GBK编码: 一个英文字符占一个字节,中文2 字节,单字符最大可占用2 个字节。 UTF-8 编码: 一个英文字符占一个字节,中文3 字节,单字符最大可占用3 个字节。 utf8mb4编码: 一个英文字符占一个字节,中文3 字节,单字符最大占4 个字节(如emoji表情4 字节)。
List使用注意事项 Arrays.asList 方法生成的List和普通的List有区别吗? Arrays.asList 方法可以把数组一键转换为 List,但生成的List和我们平时创建的List完全一致吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.Arrays;import java.util.List;public class ArraysAsListTest public static void main (String[] args) int [] arr = {1 , 2 , 3 }; List list = Arrays.asList(arr); System.out.println(list); System.out.println(list.size()); System.out.println(list.get(0 ).getClass()); } }
1 2 3 [[I@4517d9a3] 1 class [I
实践证明,这样初始化的 List 并不是我们期望的包含 3 个数字的 List,这个 List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。
其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。查看源码可知,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
1 2 3 4 5 @SafeVarargs @SuppressWarnings("varargs") public static <T> List<T> asList (T... a) { return new ArrayList<>(a); }
所以直接遍历Arrays.asList 方法得到的List会出现Bug,解决方式有两种,一种是使用 Java8 以上版本可以使用的流式操作,即 Arrays.stream 方法来转换,第二种方式是把 int 数组声明为包装类型 Integer 数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.util.Arrays;import java.util.List;import java.util.stream.Collectors;public class ArraysAsListTest public static void main (String[] args) int [] arr = {1 , 2 , 3 }; List list = Arrays.asList(arr); System.out.println(list); System.out.println(list.size()); System.out.println(list.get(0 ).getClass()); System.out.println(); int [] arr1 = {1 , 2 , 3 }; List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList()); System.out.println(list1); System.out.println(list1.size()); System.out.println(list1.get(0 ).getClass()); System.out.println(); Integer[] arr2 = {1 , 2 , 3 }; List list2 = Arrays.asList(arr2); System.out.println(list2); System.out.println(list2.size()); System.out.println(list2.get(0 ).getClass()); System.out.println(); } }
1 2 3 4 5 6 7 8 9 10 11 [[I@4517d9a3] 1 class [I [1, 2, 3] 3 class java .lang .Integer [1, 2, 3] 3 class java .lang .Integer
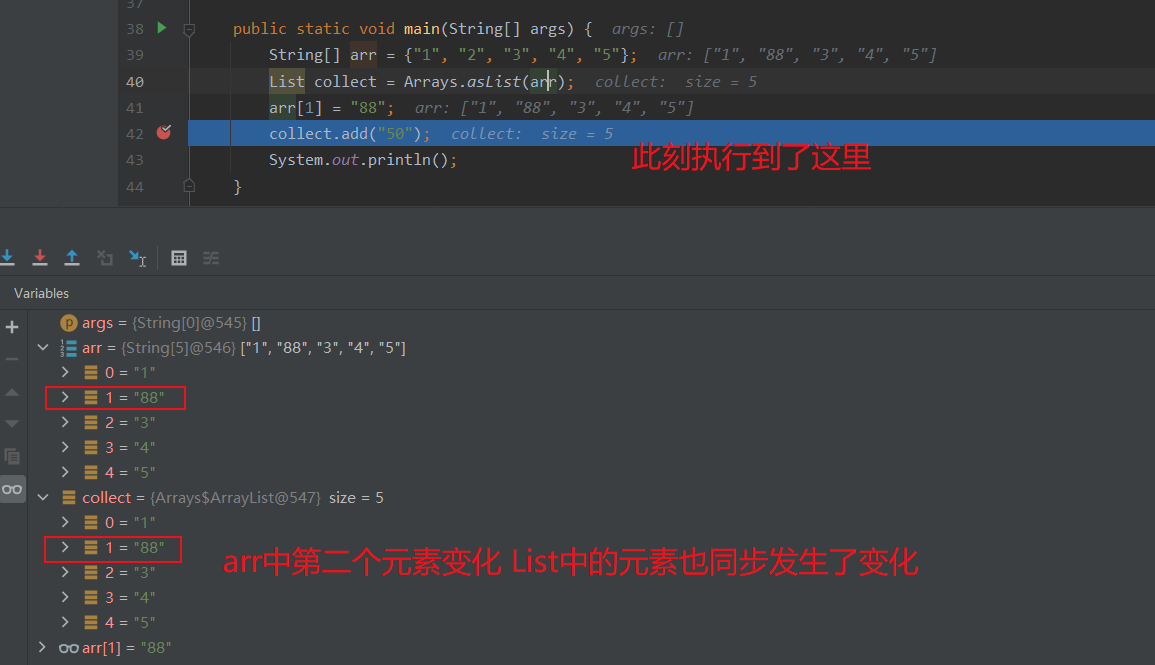
数组和Arrays.asList 方法生成的List是否相互影响? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.Arrays;import java.util.List;public static void main (String[] args) String[] arr = {"1" , "2" , "3" , "4" , "5" }; List collect = Arrays.asList(arr); arr[1 ] = "88" ; collect.add("50" ); System.out.println(); }
1 2 3 4 5 Exception in thread "main" java.lang.UnsupportedOperationException at java.util.AbstractList.add(AbstractList.java:148 ) at java.util.AbstractList.add(AbstractList.java:108 ) at JavaKnowledge.KnowledgePoints.ArraysAsListTest.ArraysAsListTest.main(ArraysAsListTest.java:42 ) Disconnected from the target VM, address: '127.0.0.1:50223' , transport: 'socket'
第一个问题:把原始数组的第二个元素从 2 修改为 88 后,尽管这一操作是在获得List之后,但asList 获得的 List 中的第二个元素也被修改为 88 了。
第二个问题:给List中调用add()方法添加元素报错了。
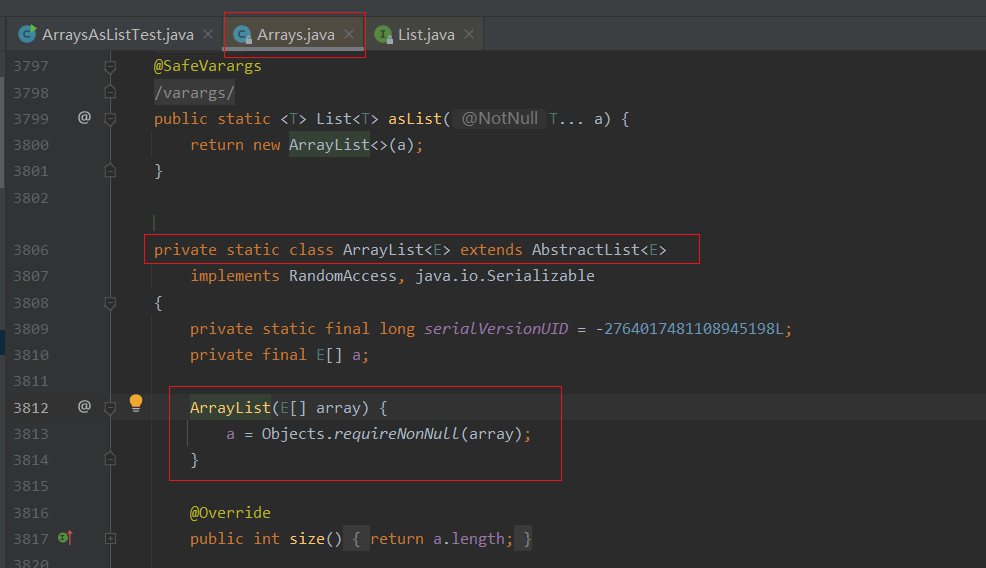
第一个问题的原因是对原始数组的修改会影响到我们获得的那个 List,看一下 ArrayList 的实现,可以发现 ArrayList 其实是直接使用了原始的数组 。所以如果把通过 Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生 Bug 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 private static class ArrayList <E > extends AbstractList <E > implements RandomAccess , java .io .Serializable private static final long serialVersionUID = -2764017481108945198L ; private final E[] a; ArrayList(E[] array) { a = Objects.requireNonNull(array); } @Override public int size () return a.length; } @Override public Object[] toArray() { return a.clone(); } @Override @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { int size = size(); if (a.length < size) return Arrays.copyOf(this .a, size, (Class<? extends T[]>) a.getClass()); System.arraycopy(this .a, 0 , a, 0 , size); if (a.length > size) a[size] = null ; return a; } @Override public E get (int index) return a[index]; } @Override public E set (int index, E element) E oldValue = a[index]; a[index] = element; return oldValue; } @Override public int indexOf (Object o) E[] a = this .a; if (o == null ) { for (int i = 0 ; i < a.length; i++) if (a[i] == null ) return i; } else { for (int i = 0 ; i < a.length; i++) if (o.equals(a[i])) return i; } return -1 ; } @Override public boolean contains (Object o) return indexOf(o) != -1 ; } @Override public Spliterator<E> spliterator () return Spliterators.spliterator(a, Spliterator.ORDERED); } @Override public void forEach (Consumer<? super E> action) Objects.requireNonNull(action); for (E e : a) { action.accept(e); } } @Override public void replaceAll (UnaryOperator<E> operator) Objects.requireNonNull(operator); E[] a = this .a; for (int i = 0 ; i < a.length; i++) { a[i] = operator.apply(a[i]); } } @Override public void sort (Comparator<? super E> c) Arrays.sort(a, c); } }
1 2 3 4 5 public static <T> T requireNonNull (T obj) { if (obj == null ) throw new NullPointerException(); return obj; }
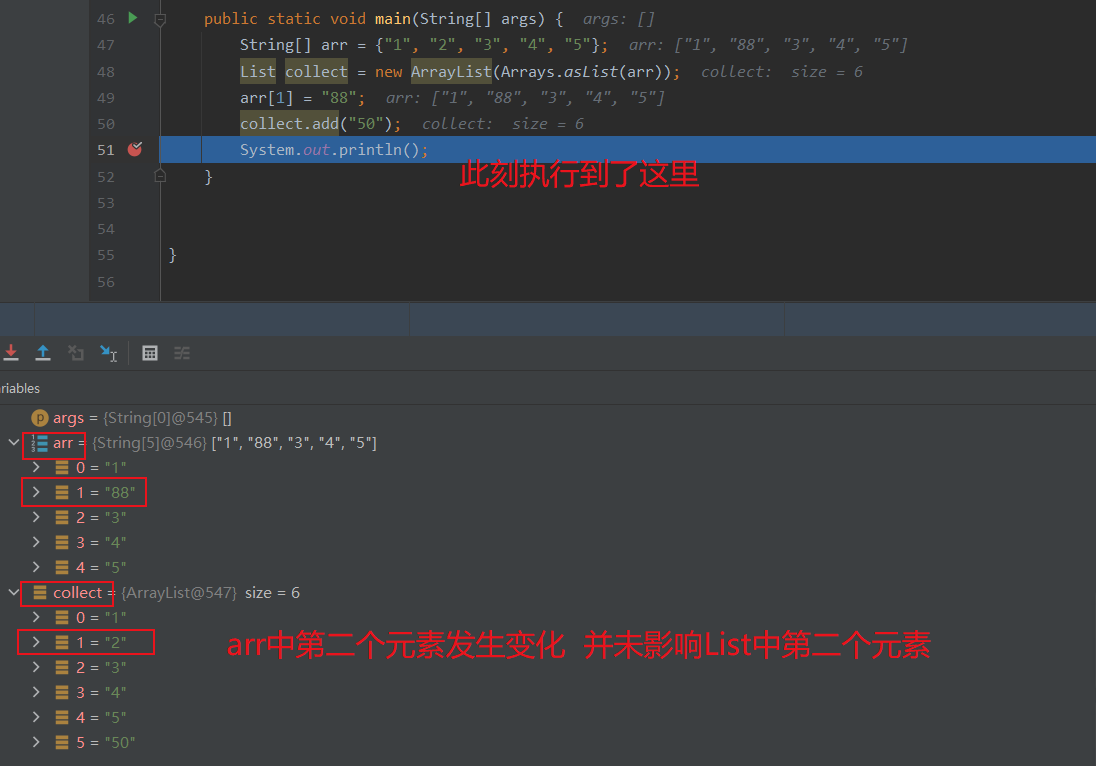
修复方式为重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
1 2 3 4 5 6 7 public static void main (String[] args) String[] arr = {"1" , "2" , "3" , "4" , "5" }; ArrayList collect = new ArrayList(Arrays.asList(arr)); arr[1 ] = "88" ; collect.add("50" ); System.out.println(); }
而且此时也不会再报错,因为此时的List是真正的 java.util.ArrayList,不是Arrays 的内部类 ArrayList,add方法也不会再报错。
第二个问题原因在于 Arrays.asList 返回的 List 不支持增删操作 。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList 。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException 。
1 2 3 public void add (int index, E element) throw new UnsupportedOperationException(); }
对List.subList得到的结果操作会影响原List? 在开发的过程中经常会用到取List中某部分数据生成一个新的List,会想到List.subList方法可以满足这一需求,但这一方法存在隐患吗? List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题。
定义一个名为 data 的静态 List 来存放 Integer 的 List,也就是说 data 的成员本身是包含了多个数字的 List。循环 1000 次,每次都从一个具有 1000 万个 Integer 的 List 中,使用 subList 方法获得一个只包含一个数字的子 List,并把这个子 List 加入 data 变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;import java.util.stream.IntStream;public class SubListTest private static List<List<Integer>> data = new ArrayList<>(); public static void main (String[] args) for (int i = 0 ; i < 1000 ; i++) { List rawList = IntStream.rangeClosed(1 , 10000000 ).boxed().collect(Collectors.toList()); data.add(rawList.subList(0 , 1 )); } } }
你可能会觉得,这个 data 变量里面最终保存的只是 1000 个具有 1 个元素的 List,不会占用很大空间,但程序运行不久就出现了 OOM:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3210 ) at java.util.Arrays.copyOf(Arrays.java:3181 ) at java.util.ArrayList.grow(ArrayList.java:261 ) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235 ) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227 ) at java.util.ArrayList.add(ArrayList.java:458 ) at java.util.stream.Collectors$$Lambda$3 /1198108795. accept(Unknown Source) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169 ) at java.util.stream.IntPipeline$4 $1. accept(IntPipeline.java:250 ) at java.util.stream.Streams$RangeIntSpliterator.forEachRemaining(Streams.java:110 ) at java.util.Spliterator$OfInt.forEachRemaining(Spliterator.java:693 ) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481 ) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471 ) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708 ) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234 ) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499 ) at JavaKnowledge.KnowledgePoints.ArraysAsListTest.SubListTest.main(SubListTest.java:20 )
**出现 OOM 的原因是,循环中的 1000 个具有 1000 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List **强引用 。
再做一个实践:首先初始化一个包含数字 1 到 15 的 ArrayList,然后通过调用 subList 方法取出 2、3、4;随后删除这个 SubList 中的元素数字 3,并打印原始的 ArrayList;最后为原始的 ArrayList 增加一个元素数字 0,遍历 SubList 输出所有元素:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.List;import java.util.stream.Collectors;import java.util.stream.IntStream;public class SubListTest02 public static void main (String[] args) List<Integer> list = IntStream.rangeClosed(1 , 15 ).boxed().collect(Collectors.toList()); List<Integer> subList = list.subList(1 , 4 ); System.out.println(subList); subList.remove(1 ); System.out.println(list); list.add(0 ); try { subList.forEach(System.out::println); } catch (Exception e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 [2 , 3 , 4 ] [1 , 2 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 ] java.util.ConcurrentModificationException at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1231 ) at java.util.ArrayList$SubList.listIterator(ArrayList.java:1091 ) at java.util.AbstractList.listIterator(AbstractList.java:299 ) at java.util.ArrayList$SubList.iterator(ArrayList.java:1087 ) at java.lang.Iterable.forEach(Iterable.java:74 ) at JavaKnowledge.KnowledgePoints.ArraysAsListTest.SubListTest02.main(SubListTest02.java:21 )
实践证明对subList进行删除,也会影响到原List。另外对原List做add操作,再次遍历subList对象时,会报ConcurrentModificationException异常。
查看ArrayList源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class ArrayList <E > extends AbstractList <E > implements List <E >, RandomAccess , Cloneable , java .io .Serializable protected transient int modCount = 0 ; private void ensureExplicitCapacity (int minCapacity) modCount++; if (minCapacity - elementData.length > 0 ) grow(minCapacity); } public void add (int index, E element) rangeCheckForAdd(index); ensureCapacityInternal(size + 1 ); System.arraycopy(elementData, index, elementData, index + 1 , size - index); elementData[index] = element; size++; } public List<E> subList (int fromIndex, int toIndex) subListRangeCheck(fromIndex, toIndex, size); return new SubList(this , offset, fromIndex, toIndex); } private class SubList extends AbstractList <E > implements RandomAccess private final AbstractList<E> parent; private final int parentOffset; private final int offset; int size; SubList(AbstractList<E> parent, int offset, int fromIndex, int toIndex) { this .parent = parent; this .parentOffset = fromIndex; this .offset = offset + fromIndex; this .size = toIndex - fromIndex; this .modCount = ArrayList.this .modCount; } public E set (int index, E element) rangeCheck(index); checkForComodification(); return l.set(index+offset, element); } public ListIterator<E> listIterator (final int index) checkForComodification(); ... } private void checkForComodification () if (ArrayList.this .modCount != this .modCount) throw new ConcurrentModificationException(); } ... } }
ArrayList 维护了一个叫作 modCount 的字段,表示 集合结构性修改的次数 。所谓结构性修改,指的是影响 List 大小的修改,所以 add 操作必然会改变 modCount 的值。
subList 方法返回的 List 是内部类 SubList ,并不是普通的 ArrayList,在初始化的时候传入了 this。SubList 中的 parent 字段就是原始的 List。SubList 初始化的时候,并没有把原始 List 中的元素复制到独立的变量中保存。可以认为 SubList 是原始 List 的视图,并不是独立的 List。双方对元素的修改会相互影响,而且 SubList 强引用了原始的 List,所以大量保存这样的 SubList 会导致 OOM 。
遍历 SubList 的时候会先获得迭代器,比较原始 ArrayList modCount 的值和 SubList 当前 modCount 的值 。获得了 SubList 后,我们为原始 List 新增了一个元素修改了其 modCount,所以判等失败抛出 ConcurrentModificationException 异常。
解决相互影响的方法有两种:第一种是不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList ;第二种是 使用 Java 8及以后的Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数 ,同样可以达到 SubList 切片的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;import java.util.stream.IntStream;public class SubListTest03 public static void main (String[] args) List<Integer> list = IntStream.rangeClosed(1 , 15 ).boxed().collect(Collectors.toList()); List<Integer> subList1 = new ArrayList<>(list.subList(1 , 4 )); System.out.println(subList1); subList1.remove(1 ); System.out.println(list); list.add(0 ); try { subList1.forEach(System.out::println); } catch (Exception e) { e.printStackTrace(); } System.out.println(); List<Integer> subList2 = list.stream().skip(1 ).limit(3 ).collect(Collectors.toList());; System.out.println(subList2); subList2.remove(1 ); System.out.println(list); list.add(0 ); try { subList2.forEach(System.out::println); } catch (Exception e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 [2 , 3 , 4 ] [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 ] 2 4 [2 , 3 , 4 ] [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 , 0 ] 2 4
不要高估List的Stream流式操作中的filter()函数性能 首先,定义一个只有一个 int 类型订单号字段的 Order 类,然后,定义一个包含 elementCount 和 loopCount 两个参数的 listSearch 方法,初始化一个具有 elementCount 个订单对象的 ArrayList,循环 loopCount 次通过filter搜索过滤得到这个 ArrayList,每次随机搜索一个订单号;另外定义另一个 mapSearch 方法,从一个具有 elementCount 个元素的 Map 中循环 loopCount 次查找随机订单号。Map 的 Key 是订单号,Value 是订单对象。对 100 万个元素的 ArrayList 和 HashMap,分别调用 listSearch 和 mapSearch 方法进行 1000 次搜索:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import java.util.List;import java.util.Map;import java.util.concurrent.ThreadLocalRandom;import java.util.function.Function;import java.util.stream.Collectors;import java.util.stream.IntStream;public class FilterTest public static void main (String[] args) int elementCount = 1000000 ; int loopCount = 1000 ; StopWatch stopWatch = new StopWatch(); stopWatch.start("List的filter搜索" ); Object list = listSearch(elementCount, loopCount); System.out.println(ObjectSizeCalculator.getObjectSize(list)); stopWatch.stop(); stopWatch.start("Map的key-value搜索" ); Object map = mapSearch(elementCount, loopCount); stopWatch.stop(); System.out.println(ObjectSizeCalculator.getObjectSize(map)); System.out.println(stopWatch.prettyPrint()); } private static Object listSearch (int elementCount, int loopCount) List<Order> list = IntStream.rangeClosed(1 , elementCount).mapToObj(i -> new Order(i)).collect(Collectors.toList()); IntStream.rangeClosed(1 , loopCount).forEach(i -> { int search = ThreadLocalRandom.current().nextInt(elementCount); Order result = list.stream().filter(order -> order.getOrderId() == search).findFirst().orElse(null ); Assert.isTrue(result != null && result.getOrderId() == search); }); return list; } private static Object mapSearch (int elementCount, int loopCount) Map<Integer, Order> map = IntStream.rangeClosed(1 , elementCount).boxed().collect(Collectors.toMap(Function.identity(), i -> new Order(i))); IntStream.rangeClosed(1 , loopCount).forEach(i -> { int search = ThreadLocalRandom.current().nextInt(elementCount); Order result = map.get(search); Assert.isTrue(result != null && result.getOrderId() == search); }); return map; } }
1 2 3 4 5 6 7 8 20861992 72388672 StopWatch '' : running time = 1804399000 ns --------------------------------------------- ns % Task name --------------------------------------------- 1737484600 096% List的filter搜索066914400 004 % Map的key-value搜索
通过实践对比可以看出,**在占用内存方面HashMap占用的内存更大,为72388672(72.38M),List占用的内存较小,为20861992(21.86M);在计算耗时方面HashMap用时更短,仅占用两个方法执行总耗时的4%,而List占用了96%**。
如果业务代码中有频繁的大 ArrayList 搜索,不要高估List的Stream流式操作中的filter()函数性能, 。类似,如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用 HashSet 进行去重。还需要注意的一点是HashMap固然查询性能好,但内存占用较大,如果有用空间换时间的需求,可以用HashMap做搜索的工作,如果没有,还是要评估下采用HashMap这样的内存占用是否可以承受 。
try-catch-finally在遇到异常时的注意事项 try-catch-finally的执行顺序是:
执行try中的代码逻辑
如果try中的代码逻辑没有抛出异常,执行finally中的代码
如果try中的代码抛出了异常,跳转到与抛出异常匹配的catch ,执行catch中对异常的处理逻辑
无论是否有异常被捕获,都会执行finally中的代码
继续执行finally之后的代码
实践一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ExceptionTest2 public static void main (String[] args) ExceptionTest2 exceptionTest2 = new ExceptionTest2(); exceptionTest2.function1(); } public void function1 () try { System.out.println("这里是try" ); }catch (Exception e) { System.out.println("这里是catch捕获了异常:" + e); }finally { System.out.println("这里是finally" ); } System.out.println("这里是try-catch-finally后的部分" ); } }
1 2 3 这里是try 这里是finally 这里是try -catch -finally 后的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExceptionTest2 public static void main (String[] args) ExceptionTest2 exceptionTest2 = new ExceptionTest2(); exceptionTest2.function2(); } public void function2 () try { System.out.println("这里是try" ); throw new Exception(); }catch (Exception e) { System.out.println("这里是catch捕获了异常:" + e); }finally { System.out.println("这里是finally" ); } System.out.println("这里是try-catch-finally后的部分" ); } }
1 2 3 4 这里是try 这里是catch 捕获了异常:java.lang.Exception 这里是finally 这里是try -catch -finally 后的部分
小心 finally 代码块中的异常会覆盖try中的异常:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class ExceptionTest public static void main (String[] args) ExceptionTest exceptionTest = new ExceptionTest(); exceptionTest.function1(); } public void function1 () try { System.out.println("try中的异常" ); throw new RuntimeException("try中的异常" ); } finally { System.out.println("finally中的异常" ); throw new RuntimeException("finally中的异常" ); } } }
1 2 3 4 5 6 try 中的异常finally 中的异常Exception in thread "main" java.lang.RuntimeException: finally 中的异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.function1(ExceptionTest.java:27 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.main(ExceptionTest.java:11 ) Disconnected from the target VM, address: '127.0.0.1:59938' , transport: 'socket'
出现这个问题的原因是一个方法无法出现两个异常。修复方式是,finally 代码块自己负责异常捕获和处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class ExceptionTest public static void main (String[] args) ExceptionTest exceptionTest = new ExceptionTest(); exceptionTest.function2(); } public void function2 () try { System.out.println("try中的异常" ); throw new RuntimeException("try中的异常" ); } finally { System.out.println("finally中的异常" ); try { throw new RuntimeException("finally中的异常" ); }catch (Exception ex) { System.out.println("finally中的异常:" + ex); } } } }
1 2 3 4 5 6 try 中的异常finally 中的异常finally 中的异常:java.lang.RuntimeException: finally 中的异常Exception in thread "main" java.lang.RuntimeException: try 中的异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.function2(ExceptionTest.java:31 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.main(ExceptionTest.java:12 )
或者可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class ExceptionTest public static void main (String[] args) throws Exception ExceptionTest exceptionTest = new ExceptionTest(); exceptionTest.function3(); } public void function3 () throws Exception Exception e = null ; try { System.out.println("try中的异常" ); throw new RuntimeException("try中的异常" ); } catch (Exception ex) { e = ex; }finally { System.out.println("finally中的异常" ); try { throw new RuntimeException("finally中的异常" ); }catch (Exception ex) { if (e != null ) { e.addSuppressed(ex); }else { e = ex; } } } if (e != null ) { throw e; } } }
1 2 3 4 5 6 7 8 try 中的异常finally 中的异常Exception in thread "main" java.lang.RuntimeException: try 中的异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.function3(ExceptionTest.java:46 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.main(ExceptionTest.java:13 ) Suppressed: java.lang.RuntimeException: finally 中的异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.ExceptionTest.function3(ExceptionTest.java:52 ) ... 1 more
其实 try-with-resources 语句的实现就是这个思路,对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。实践写一个demo,其 read 和 close 方法都会抛出异常:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class TryWithResourceTest implements AutoCloseable public static void main (String[] args) throws Exception TryWithResourceTest tryWithResourceTest = new TryWithResourceTest(); try { tryWithResourceTest.read(); } finally { tryWithResourceTest.close(); } } public void read () throws Exception throw new Exception("读取异常" ); } @Override public void close () throws Exception throw new Exception("关闭异常" ); } }
1 2 3 Exception in thread "main" java.lang.Exception: 关闭异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.close(TryWithResourceTest.java:30 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.main(TryWithResourceTest.java:14 )
finally 中的异常覆盖了 try 中异常,现在我们改为 try-with-resources 方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class TryWithResourceTest implements AutoCloseable public static void main (String[] args) throws Exception try (TryWithResourceTest tryWithResourceTest = new TryWithResourceTest()) { tryWithResourceTest.read(); } } public void read () throws Exception throw new Exception("读取异常" ); } @Override public void close () throws Exception throw new Exception("关闭异常" ); } }
1 2 3 4 5 6 Exception in thread "main" java.lang.Exception: 读取异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.read(TryWithResourceTest.java:25 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.main(TryWithResourceTest.java:18 ) Suppressed: java.lang.Exception: 关闭异常 at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.close(TryWithResourceTest.java:30 ) at JavaKnowledge.KnowledgePoints.ExceptionTest.TryWithResourceTest.main(TryWithResourceTest.java:19 )
实践验证了try 和 finally 中的异常信息都可以得到保留。
异常的抛出不要太宽泛
在实际项目中不要把异常的很宽泛,这样不利于出现问题时的排查和定位:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class ExceptionTest1 public static void main (String[] args) throws Exception ExceptionTest1 exceptionTest1 = new ExceptionTest1(); exceptionTest1.function1(); } public void function1 () try { ListEmptyWrong(); } catch (Exception ex) { System.out.println(ex); } try { ListOverLongWrong(); } catch (Exception ex) { System.out.println(ex); } } private void ListEmptyWrong () throws Exception throw MyExceptions.LIST_ERROR ; } private void ListOverLongWrong () throws Exception throw MyExceptions.LIST_ERROR; } }
1 2 3 4 5 public class MyExceptions extends Exception public static Exception LIST_ERROR = new Exception("List存在异常的提示message" ); }
1 2 java.lang.Exception: List存在异常的提示message java.lang.Exception: List存在异常的提示message
将异常的抛出更加具体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class ExceptionTest1 public static void main (String[] args) throws Exception ExceptionTest1 exceptionTest1 = new ExceptionTest1(); exceptionTest1.function2(); } public void function1 () try { ListEmptyWrong(); } catch (Exception ex) { System.out.println(ex); } try { ListOverLongWrong(); } catch (Exception ex) { System.out.println(ex); } } private void ListEmptyWrong () throws Exception throw MyExceptions.LIST_ERROR ; } private void ListOverLongWrong () throws Exception throw MyExceptions.LIST_ERROR; } public void function2 () try { throw new Exception(); } catch (Exception ex) { System.out.println("异常提示:" + MyExceptions.listEmpty()); } try { throw new Exception(); } catch (Exception ex) { System.out.println("异常提示:" + MyExceptions.listOverLong()); } } }
1 2 3 4 5 6 7 8 9 10 11 12 public class MyExceptions extends Exception public static Exception LIST_ERROR = new Exception("List存在异常的提示message" ); public static Exception listEmpty () return new Exception("List为空的异常message" ); } public static Exception listOverLong () return new Exception("List过大的异常message" ); } }
1 2 异常提示:java.lang.Exception: List为空的异常message 异常提示:java.lang.Exception: List过大的异常message
Java序列化serialVersionUID一定要手动赋值 serialVersionUID是什么? serialVersionUID 是用于在序列化 反序列化 。
序列化运行时将一个版本号(称为serialVersionUID)与每个可序列化类相关联,该版本号在反序列化期间用于验证序列化对象的发送方和接收方是否为该对象加载了与序列化兼容的类。如果接收方为对象加载的类与相应发送方类的serialVersionUID不同,则反序列化将导致InvalidClassException 。
序列化类可以通过声明名为 serialVersionUID 的字段显式声明自己的 serialVersionUID,且该字段必须是static、final的且类型为long,例如:
1 2 3 4 5 public class Person static final long serialVersionUID = 1L ; String name; Integer age; }
如果不使用会发生什么? Java对象序列化规范中标明,如果可序列化类没有显式声明serialVersionUID 。但是,强烈建议所有可序列化类显式声明serialVersionUID值 默认的 serialVersionUID 计算对类详细信息高度敏感 。因此,为了保证在不同的Java编译器实现中SerialVersionUID值是一致的,可序列化类必须声明一个显式的SerialVersionUID值。还强烈建议显式 serialVersionUID 声明尽可能使用 private 修饰符,这样可以确保子类不会意外地继承父类的 serialVersionUID,从而避免在序列化和反序列化时出现潜在的兼容性问题 。
实践 不设置serialVersionUID时正常序列化和反序列化 定义一个Student类,并注意一定要实现序列化接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.io.Serializable;public class Student implements Serializable private int age; private String name; public Student (int age, String name) this .age = age; this .name = name; } @Override public String toString () return "Student{" + "age=" + age + ", name='" + name + '\'' + '}' ; } }
写一个测试类,逻辑是先把 Student对象序列化到 Student.txt 文件,然后再将 Student.txt 文件反序列化成对象然后打印输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import java.io.*;public class serialVersionUIDTest public static void main (String[] args) serial(); deserial(); } private static void serial () Student student = new Student(12 , "Chris" ); try { FileOutputStream fileOutputStream = new FileOutputStream("Student.txt" ); ObjectOutputStream objectOutputStream= new ObjectOutputStream(fileOutputStream); objectOutputStream.writeObject(student); objectOutputStream.flush(); } catch (Exception exception) { exception.printStackTrace(); } } private static void deserial () try { FileInputStream fis = new FileInputStream("Student.txt" ); ObjectInputStream ois = new ObjectInputStream(fis); Student student = (Student) ois.readObject(); ois.close(); System.out.println(student.toString()); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
1 Student{age=12 , name='Chris' }
实践可以验证:序列化文件Student.txt 中的内容被反序列化成为原来的Student对象,表明反序列化成功。
类增加字段后进行反序列化 Student类增加一个weight字段,并且这次只反序列化,用于实践验证之前的serialVersionUID :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.io.Serializable;public class Student implements Serializable private int age; private String name; private int weight; public Student (int age, String name,int weight) this .age = age; this .name = name; this .weight = weight; } @Override public String toString () return "Student{" + "age=" + age + ", name='" + name + '\'' + ", weight='" + weight + '\'' + '}' ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import java.io.*;public class serialVersionUIDTest public static void main (String[] args) deserial(); } private static void serial () Student student = new Student(12 , "Chris" , 120 ); try { FileOutputStream fileOutputStream = new FileOutputStream("Student.txt" ); ObjectOutputStream objectOutputStream= new ObjectOutputStream(fileOutputStream); objectOutputStream.writeObject(student); objectOutputStream.flush(); } catch (Exception exception) { exception.printStackTrace(); } } private static void deserial () try { FileInputStream fis = new FileInputStream("Student.txt" ); ObjectInputStream ois = new ObjectInputStream(fis); Student student = (Student) ois.readObject(); ois.close(); System.out.println(student.toString()); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 java.io.InvalidClassException: JavaKnowledge.KnowledgePoints.serialVersionUIDTest.Student; local class incompatible : stream classdesc serialVersionUID 7930895883702140645 , local class serialVersionUID 3548451356213450738 at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:616 ) at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1843 ) at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1713 ) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2000 ) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1535 ) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:422 ) at JavaKnowledge.KnowledgePoints.serialVersionUIDTest.serialVersionUIDTest.deserial(serialVersionUIDTest.java:32 ) at JavaKnowledge.KnowledgePoints.serialVersionUIDTest.serialVersionUIDTest.main(serialVersionUIDTest.java:13 )
实践证明:修改类的字段信息后,如果没有手动声明serialVersionUID,则现在的serialVersionUID和之前的serialVersionUID会不一致,因为自动生成的serialVersionUID是根据类的详细信息计算的,字段发生变化,导致生成了新的serialVersionUID,所以反序列化会失败 。
手动显式设置serialVersionUID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import java.io.Serializable;public class Student implements Serializable static final long serialVersionUID = 1L ; private int age; private String name; public Student (int age, String name) this .age = age; this .name = name; } @Override public String toString () return "Student{" + "age=" + age + ", name='" + name + '\'' + '}' ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import java.io.*;public class serialVersionUIDTest public static void main (String[] args) serial(); deserial(); } private static void serial () Student student = new Student(12 , "Chris" ); try { FileOutputStream fileOutputStream = new FileOutputStream("Student.txt" ); ObjectOutputStream objectOutputStream= new ObjectOutputStream(fileOutputStream); objectOutputStream.writeObject(student); objectOutputStream.flush(); } catch (Exception exception) { exception.printStackTrace(); } } private static void deserial () try { FileInputStream fis = new FileInputStream("Student.txt" ); ObjectInputStream ois = new ObjectInputStream(fis); Student student = (Student) ois.readObject(); ois.close(); System.out.println(student.toString()); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
1 Student{age=12 , name='Chris' }
增加字段weight:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import java.io.Serializable;public class Student implements Serializable static final long serialVersionUID = 1L ; private int age; private String name; private int weight; public Student (int age, String name,int weight) this .age = age; this .name = name; this .weight = weight; } @Override public String toString () return "Student{" + "age=" + age + ", name='" + name + '\'' + ", weight='" + weight + '\'' + '}' ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import java.io.*;public class serialVersionUIDTest public static void main (String[] args) deserial(); } private static void serial () Student student = new Student(12 , "Chris" , 120 ); try { FileOutputStream fileOutputStream = new FileOutputStream("Student.txt" ); ObjectOutputStream objectOutputStream= new ObjectOutputStream(fileOutputStream); objectOutputStream.writeObject(student); objectOutputStream.flush(); } catch (Exception exception) { exception.printStackTrace(); } } private static void deserial () try { FileInputStream fis = new FileInputStream("Student.txt" ); ObjectInputStream ois = new ObjectInputStream(fis); Student student = (Student) ois.readObject(); ois.close(); System.out.println(student.toString()); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
1 Student{age=12 , name='Chris' , weight='0' }
实践可知:此时可以正常反序列化Student类增加字段之前生成的Student对象,此时新增的字段weight值为默认值0,因为之前不存在这个字段,所以反序列化后赋值为默认值 。
注解可以继承吗? 定义一个包含 value 属性的 MyAnnotation 注解,可以标记在方法或类上:
1 2 3 4 5 6 7 8 9 10 11 12 import java.lang.annotation.ElementType;import java.lang.annotation.Retention;import java.lang.annotation.RetentionPolicy;import java.lang.annotation.Target;@Target({ElementType.METHOD, ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface MyAnnotation { String value () ; }
定义一个标记了 @MyAnnotation 注解的父类 Father,设置 value 为 字符串 “这是类上的注解value值”;同时这个类的 foo 方法也标记了 @MyAnnotation 注解,设置 value 为 字符串 “这是方法的注解value值”。接下来,定义一个子类 Son 继承 Father 父类,并重写父类的 foo 方法,子类的 foo 方法和类上都没有 @MyAnnotation 注解。
1 2 3 4 5 6 7 8 9 @MyAnnotation(value = "这是类上的注解value值") public class Father @MyAnnotation(value = "这是方法的注解value值") public void foo () } }
1 2 3 4 5 6 7 8 public class Son extends Father @Override public void foo () } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class AnnotationTest public static void main (String[] args) throws NoSuchMethodException function1(); } private static String getAnnotationValue (MyAnnotation annotation) if (annotation == null ) return "" ; return annotation.value(); } public static void function1 () throws NoSuchMethodException Father father = new Father(); System.out.println("父类:" + getAnnotationValue(father.getClass().getAnnotation(MyAnnotation.class))); System.out.println("父类方法:" + getAnnotationValue(father.getClass().getMethod("foo" ).getAnnotation(MyAnnotation.class))); Son son = new Son(); System.out.println("子类:" + getAnnotationValue(son.getClass().getAnnotation(MyAnnotation.class))); System.out.println("子类方法:" + getAnnotationValue(son.getClass().getMethod("foo" ).getAnnotation(MyAnnotation.class))); } }
1 2 3 4 父类:这是类上的注解value值 父类方法:这是方法的注解value值 子类: 子类方法:
在注解上标记 @Inherited 元注解可以实现注解的继承,实践一下在 @MyAnnotation 注解上标记 @Inherited,是否可以实现子类继承父类的注解:
1 2 3 4 5 6 7 8 import java.lang.annotation.*;@Target({ElementType.METHOD, ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Inherited public @interface MyAnnotation { String value () ; }
1 2 3 4 父类:这是类上的注解value值 父类方法:这是方法的注解value值 子类:这是类上的注解value值 子类方法:
实践可知:子类可以获得父类上的注解,而子类 foo 方法虽然是重写父类方法,并且注解本身也支持继承,但还是无法获得方法上的注解 ,原因在于**@Inherited 只能实现类上的注解继承**。Spring 提供了 AnnotatedElementUtils 类,用于处理注解的继承问题,其中包含一个 findMergedAnnotation 方法,可以找到父类和父类方法上的注解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import org.springframework.core.annotation.AnnotatedElementUtils;public class AnnotationTest public static void main (String[] args) throws NoSuchMethodException function2(); } private static String getAnnotationValue (MyAnnotation annotation) if (annotation == null ) return "" ; return annotation.value(); } public static void function2 () throws NoSuchMethodException Father father = new Father(); System.out.println("父类:" + getAnnotationValue(father.getClass().getAnnotation(MyAnnotation.class))); System.out.println("父类方法:" + getAnnotationValue(father.getClass().getMethod("foo" ).getAnnotation(MyAnnotation.class))); Son son = new Son(); System.out.println("子类:" + getAnnotationValue(AnnotatedElementUtils.findMergedAnnotation(son.getClass(), MyAnnotation.class))); System.out.println("子类方法:" + getAnnotationValue(AnnotatedElementUtils.findMergedAnnotation(son.getClass().getMethod("foo" ), MyAnnotation.class))); } }
1 2 3 4 父类:这是类上的注解value值 父类方法:这是方法的注解value值 子类:这是类上的注解value值 子类方法:这是方法的注解value值
实践可知:此时子类可以获取到父类的类上和方法上的注解的属性value的值 。
遍历集合时remove或add操作注意事项 不可以在 foreach 循环里进行元素的 remove/add 操作,remove 元素需要使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁 。foreach 语法底层其实还是依赖 Iterator ,不过, remove/add 操作直接调用的是集合自己的方法,而不是 Iterator 的 remove/add方法。这就导致 Iterator 莫名其妙地发现自己有元素被 remove/add ,然后,它就会抛出一个 ConcurrentModificationException 来提示用户发生了并发修改异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.ArrayList;import java.util.Iterator;public class IteratorRemoveExample public static void main (String[] args) ArrayList<Integer> numbers = new ArrayList<>(); numbers.add(1 ); numbers.add(2 ); numbers.add(3 ); numbers.add(4 ); Iterator<Integer> iterator = numbers.iterator(); while (iterator.hasNext()) { Integer number = iterator.next(); if (number == 2 ) { numbers.remove(number); } } } }
1 2 3 4 Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901 ) at java.util.ArrayList$Itr.next(ArrayList.java:851 ) at JavaKnowledge.IteratorTest.IteratorRemoveExample.main(IteratorRemoveExample.java:21 )
正确地remove/add:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.ArrayList;import java.util.Iterator;public class IteratorRemoveExample public static void main (String[] args) ArrayList<Integer> numbers = new ArrayList<>(); numbers.add(1 ); numbers.add(2 ); numbers.add(3 ); numbers.add(4 ); Iterator<Integer> iterator = numbers.iterator(); while (iterator.hasNext()) { Integer number = iterator.next(); if (number == 2 ) { iterator.remove(); } } System.out.println(numbers); } }
BeanUtils.copyProperties使用避坑实践 变量名不一致 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class User private String name; private Integer aGe; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import org.springframework.beans.BeanUtils;public class Test public static void main (String[] args) Person person = new Person("Chris" , 12 ); User user = new User(); BeanUtils.copyProperties(person, user); System.out.println(user); } }
1 User(name=Chris, aGe=null )
变量类型不一致 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class User private String name; private String age; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import org.springframework.beans.BeanUtils;public class Test public static void main (String[] args) Person person = new Person("Chris" , 12 ); User user = new User(); BeanUtils.copyProperties(person, user); System.out.println(user); } }
1 User(name=Chris, age=null )
loombook在遇到Boolean类型变量时,变量名为is开头会出拷贝异常 不用loombook:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Person private String name; private Integer age; private Boolean isMale; public Boolean getMale () return isMale; } public void setMale (Boolean male) isMale = male; } public String getName () return name; } public Integer getAge () return age; } public void setName (String name) this .name = name; } public void setAge (Integer age) this .age = age; } public Person (String name, Integer age, Boolean isMale) this .name = name; this .age = age; this .isMale = isMale; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class User private String name; private Integer age; private boolean isMale; public User () } public boolean isMale () return isMale; } public void setMale (boolean male) isMale = male; } public void setName (String name) this .name = name; } public void setAge (Integer age) this .age = age; } public String getName () return name; } public Integer getAge () return age; } }
1 2 3 4 5 6 7 8 9 10 11 public class Test public static void main (String[] args) Person person = new Person("Chris" , 12 , true ); User user = new User(); BeanUtils.copyProperties(person, user); System.out.println(user.getName()); System.out.println(user.getAge()); System.out.println(user.isMale()); } }
实践可知:手动生成get和set方法,且boolean类型变量名前缀为is时不会产生拷贝异常的问题。原因在与Person中的getMale方法与User中的setMale方法呼应,所以能正确从Person中获取isMale变量的值赋值到User中的isMale变量中。下面看一下使用loombook的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; private Boolean isMale; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class User private String name; private Integer age; private boolean isMale; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import org.springframework.beans.BeanUtils;public class Test public static void main (String[] args) Person person = new Person("Chris" , 12 , true ); User user = new User(); BeanUtils.copyProperties(person, user); System.out.println(user); } }
1 User(name=Chris, age=12 , isMale=false )
实践可知,在使用loombook且boolean类型变量名前缀为is时会产生拷贝异常的问题,无法正确拷贝。原因在于Person通过loombook 生成的获取Boolean类型的isMale变量 的方法为getIsMale ,而在User中通过loombook 生成的获取boolean类型的isMale变量 的方法为isMale ,两个命名规则不一致,所以BeanUtils.copyProperties 。
位于不同类中同名的内部类拷贝会出现异常 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; private Person.InnerClass innerClass; @Data @AllArgsConstructor @NoArgsConstructor public static class InnerClass public String innerName; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Data @AllArgsConstructor @NoArgsConstructor public class User private String name; private Integer age; private User.InnerClass innerClass; @Data @AllArgsConstructor @NoArgsConstructor public static class InnerClass public String innerName; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import org.springframework.beans.BeanUtils;public class Test public static void main (String[] args) Person person = new Person("Chris" , 12 , new Person.InnerClass("innerChris" )); User user = new User(); BeanUtils.copyProperties(person, user); System.out.println(user.getName()); System.out.println(user.getAge()); System.out.println(user.getInnerClass()); } }
未注意BeanUtils.copyProperties是浅拷贝 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Student private String name; private Integer score; }
1 2 3 4 5 6 7 8 9 10 11 12 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; private Student student; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import org.springframework.beans.BeanUtils;public class BeanUtilsTypeErrorTest public static void main (String[] args) Student student = new Student("John" , 90 ); Person sourcePerson = new Person("Chris" , 12 , student); Person targetPerson = new Person(); BeanUtils.copyProperties(sourcePerson, targetPerson); System.out.println(targetPerson.getStudent()); sourcePerson.getStudent().setName("Bear" ); sourcePerson.getStudent().setScore(95 ); System.out.println(targetPerson.getStudent()); } }
1 2 Student(name=John, score=90 ) Student(name=Bear, score=95 )
实践可知,拷贝Person对象时,被拷贝的sourcePerson中类型为Student的对象student的引用被拷贝到了targetPerson中的Student成员变量中,也就是说sourcePerson和targetPerson中的student指向的是同一个地址,所以对这个student对象进行修改,从源Person和目标Person中查看成员变量student的内容都是被修改后的内容了 。
存在List类型的成员变量时无法通过BeanUtils.copyProperties直接拷贝 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.List;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; private Student student; private List<Integer> taskIdList; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Student private String name; private Integer score; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import org.springframework.beans.BeanUtils;import java.util.ArrayList;import java.util.List;public class BeanUtilsTypeErrorTest public static void main (String[] args) Student student = new Student("John" , 90 ); List<Integer> taskIdList = new ArrayList<>(); taskIdList.add(1 ); taskIdList.add(2 ); taskIdList.add(3 ); taskIdList.add(4 ); taskIdList.add(5 ); Person sourcePerson = new Person("Chris" , 12 , student, taskIdList); Person targetPerson = new Person(); BeanUtils.copyProperties(sourcePerson, targetPerson); System.out.println(targetPerson.getTaskIdList()); sourcePerson.getTaskIdList().remove(2 ); System.out.println(targetPerson.getTaskIdList()); } }
1 2 [1 , 2 , 3 , 4 , 5 ] [1 , 2 , 4 , 5 ]
实践可知,存在 BeanUtils.copyProperties BeanUtils.copyProperties拷贝 。
那么如果遇到上述情况,想复制该怎么办呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.List;@Data @AllArgsConstructor @NoArgsConstructor public class Person private String name; private Integer age; private Student student; private List<Integer> taskIdList; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @AllArgsConstructor @NoArgsConstructor public class Student private String name; private Integer score; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import org.springframework.beans.BeanUtils;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;public class BeanUtilsTypeErrorTest public static void main (String[] args) Student student = new Student("John" , 90 ); List<Integer> taskIdList = new ArrayList<>(); taskIdList.add(1 ); taskIdList.add(2 ); taskIdList.add(3 ); taskIdList.add(4 ); taskIdList.add(5 ); Person sourcePerson = new Person("Chris" , 12 , student, taskIdList); System.out.println("复制前Student:" + sourcePerson.getStudent()); Person targetPerson = new Person(); BeanUtils.copyProperties(sourcePerson, targetPerson); Student sourceStudent = sourcePerson.getStudent(); Student targetStudent = new Student(); BeanUtils.copyProperties(sourceStudent, targetStudent); targetPerson.setStudent(targetStudent); sourcePerson.getStudent().setName("Bear" ); sourcePerson.getStudent().setScore(95 ); List<Integer> sourceTaskIdList = sourcePerson.getTaskIdList(); List<Integer> targetTaskIdList = sourceTaskIdList.stream().collect(Collectors.toList()); targetPerson.setTaskIdList(targetTaskIdList); System.out.println("复制后Student:" + targetPerson.getStudent()); System.out.println(targetPerson.getTaskIdList()); sourcePerson.getTaskIdList().remove(2 ); System.out.println(targetPerson.getTaskIdList()); } }
1 2 3 4 复制前Student:Student(name=John, score=90 ) 复制后Student:Student(name=John, score=90 ) [1 , 2 , 3 , 4 , 5 ] [1 , 2 , 3 , 4 , 5 ]
实践可知:Student和List都被正确的拷贝了一份至目标Person 。
低估了BeanUtils.copyProperties的性能损耗 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import org.springframework.beans.BeanUtils;public class BeanUtilsTypeErrorTest public static void main (String[] args) Student student = new Student("John" , 90 ); Person sourcePerson = new Person("Chris" , 12 , student); Person targetPerson1 = new Person(); Person targetPerson2 = new Person(); long beginTime1 = System.currentTimeMillis(); for (int i = 0 ; i < 1000000 ; i++) { BeanUtils.copyProperties(sourcePerson, targetPerson1); } System.out.println(targetPerson1); System.out.println("BeanUtils.copyProperties复制用时:" + (System.currentTimeMillis() - beginTime1)); long beginTime2 = System.currentTimeMillis(); for (int i = 0 ; i < 1000000 ; i++) { targetPerson2.setName(sourcePerson.getName()); targetPerson2.setAge(sourcePerson.getAge()); targetPerson2.setStudent(sourcePerson.getStudent()); } System.out.println(targetPerson2); System.out.println("手动set复制的方式用时:" + (System.currentTimeMillis() - beginTime2)); } }
1 2 3 4 Person(name=Chris, age=12 , student=Student(name=John, score=90 )) BeanUtils.copyProperties复制用时:1876 Person(name=Chris, age=12 , student=Student(name=John, score=90 )) 手动set复制的方式用时:4
实践可知:BeanUtils.copyProperties比手动set复制的方式性能差很多倍,原因在于BeanUtils.copyProperties底层是通过反射实现的。